
Nov 16, 2020
For fair and equal healthcare, we need fair and bias-free AI
Artificial intelligence (AI) has the potential to make healthcare more accessible, affordable, and effective, but it can also inadvertently lead to erroneous conclusions and thereby amplify existing inequalities. Mitigating these risks requires awareness of the bias that can creep into AI algorithms – and how to prevent it through careful design and implementation. In a widely reported study published in Science last year, a group of researchers at the University of California revealed that an algorithm used by US hospitals to flag high-risk patients for enhanced medical attention exhibited significant racial bias. Black patients were less likely to be flagged for additional care than white patients, even when they were equally sick [1]. Technically, there was nothing wrong with the algorithm, and its creators never intended it to discriminate anyone. In fact, they designed the algorithm to be ‘race-blind’. Then what caused it to be biased? The problem with the algorithm was that it predicted future healthcare costs, rather than future illness, to identify high-risk patients in need of extra care. Because Black patients in the US on average tend to have more limited access to high-quality healthcare, they typically incur lower costs than white patients with the same conditions. Relying on healthcare costs as a proxy for health risk and healthcare needs therefore put Black patients at a considerable disadvantage. When the researchers ran a simulation with clinical data instead, the percentage of people referred for additional medical care who were Black increased from 17.7 to 46.5% [i]. This study highlights how deep-rooted disparities in healthcare systems can be unintentionally reinforced by AI algorithms. With careful design, AI has the promise to create a healthier and fairer future for all. But there’s also a risk that we end up encoding current and past inequalities.
With careful design, AI has the promise to create a healthier and fairer future for all. But there’s also a risk that we end up encoding current and past inequalities.
It’s a risk that is by now well recognized in the healthcare community. According to a recent survey conducted by the Healthcare Information and Management Systems Society (HIMSS), 93% of healthcare and healthcare IT professionals are at least somewhat concerned that existing biases may be transferred into AI algorithms [2].
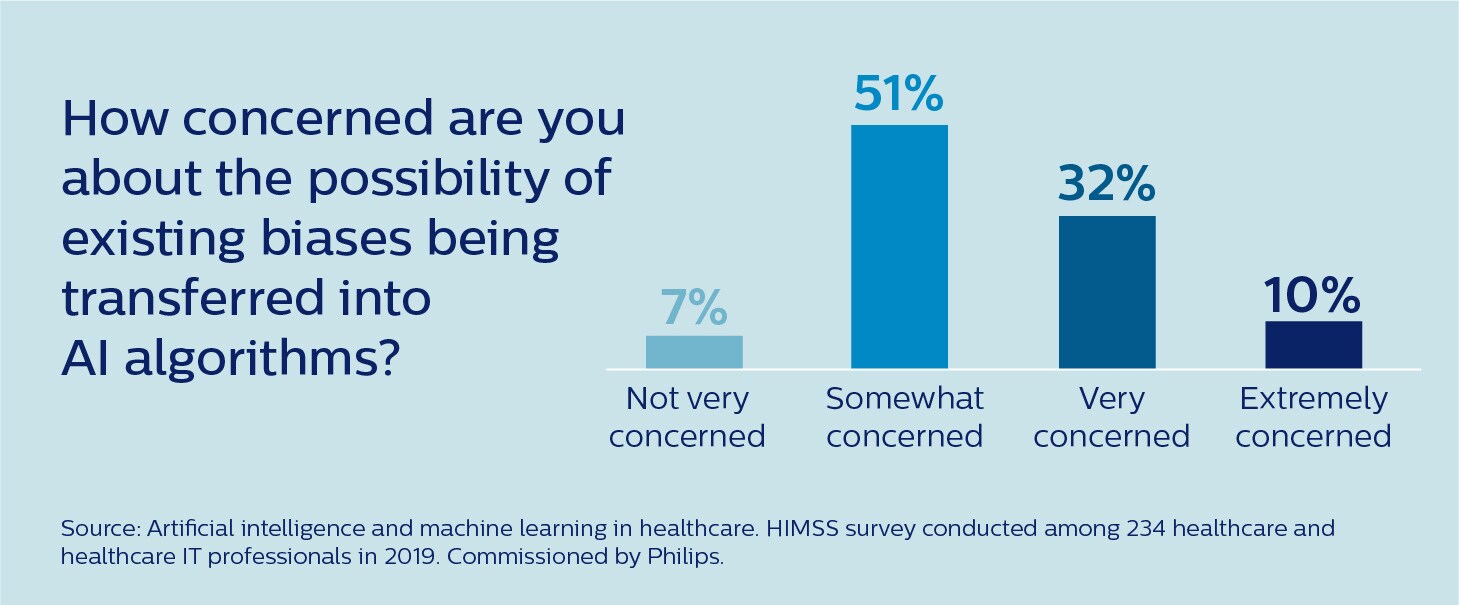
So how can we ensure that AI is fair and helps to reduce existing health disparities rather than exacerbate them?
How bias can arise in AI
To effectively mitigate the risk of bias in healthcare AI, we must first understand the different ways it can arise. Arguably the biggest pitfall in developing and implementing AI is that we accept its output uncritically without sufficiently scrutinizing its input and underlying design choices. It is a well-documented psychological phenomenon that people tend to take computer-based recommendations at face value [3]. AI algorithms lend a veneer of objectivity and impartiality to any decision-making process. The truth is, however, that an algorithm’s output is very much shaped by the data we feed into it – and by other human choices that guide the development and deployment of the algorithm. These choices may be subject to biases that unintentionally put certain groups at a disadvantage.
Arguably the biggest pitfall in developing and implementing AI is that we accept its output uncritically without sufficiently scrutinizing its input and underlying design choices.
In healthcare, there is a high risk of bias creeping in right from the start – when data are selected to train an algorithm. That is because the available data sets may not be representative of the target population. For example, women and people of color are notoriously underrepresented in clinical trials [4,5]. Genomics research also has a long way to go toward more inclusivity, with 81% of participants being of European ancestry [6]. With biased data comes the danger of biased AI. Researchers have raised concerns that algorithms analyzing skin images could miss malignant melanomas in people of color, because these algorithms are predominantly trained on images of white patients [7]. Similarly, some have questioned whether algorithms designed to prioritize care for COVID-19 patients are actually increasing the disease burden on underserved populations [8]. If these populations lack access to COVID-19 testing, algorithms may fail to factor in their needs and characteristics because they are underrepresented in the training data. Choices made during data processing and algorithm development can also contribute to bias, even if the data itself is free of bias. For example, relevant differences between populations may be overlooked in the pursuit of a one-size-fits-all model. We know that many diseases present differently in men and women, whether it’s cardiovascular disease, diabetes, or mental health disorders such as depression and autism. If algorithms don’t take such differences into account, they could magnify existing gender inequalities [9]. Finally, it is important to realize that what is fair and inclusive in one context is not necessarily so in another. A telling example is an algorithm that was developed at a Washington hospital to annotate cancer patient reports with test results based on clinician notes. The algorithm performed very well at the Washington hospital. But when it was applied in a Kentucky hospital, its performance plummeted. The cause? Clinicians in Kentucky used different terminology in their notes [10]. To summarize, bias can occur at any phase of AI development and deployment, from using biased datasets to deploying algorithms in a different context than the one it was trained for:
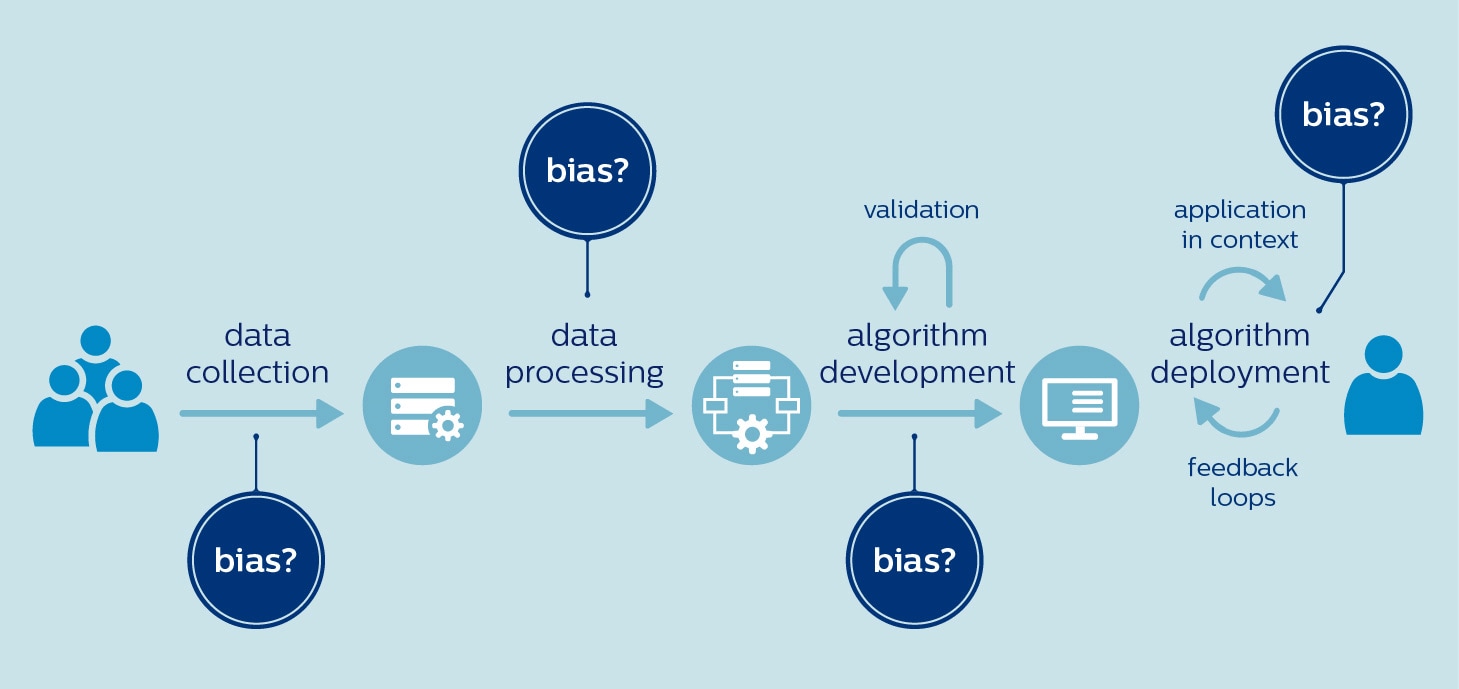
The question, then, is what we can do about it.
Embracing fairness as a guiding principle
Public and regulatory bodies, as well as private industry players, have recognized the need for clear guiding principles and policies to prevent bias in AI. In a bid to promote the beneficial and responsible use of AI, the European Commission established a High-Level Expert Group (HLEG) that has published guidelines on trustworthy AI, including “diversity, non-discrimination and fairness”. In the U.S., the Algorithmic Accountability Act has been proposed, which would require companies to assess their AI systems for risks of unfair, biased, or discriminatory decisions. And in China, the National Medical Products Administration (NMPA) recently issued new regulation [in Chinese] to control the risk of bias in medical devices. At Philips, we have embraced fairness as one of our five guiding principles for the responsible use of AI. We believe that AI-enabled solutions should be developed and validated with data that is representative of the target group for the intended use, while avoiding bias and discrimination.
Fairness must be a guiding principle for the responsible use of AI.
Of course, principles are only as valuable as the practices that back them up. Because many of the potential sources of bias are hard-baked into today’s healthcare data, reflecting historical and socio-economic inequalities, we have formidable challenges to overcome as an industry. In fact, most of these challenges are not specific to AI and data science – they call for wider, systemic changes such as improving access to care for the disadvantaged and making medical research more inclusive. When it comes to AI and data science specifically, more awareness is needed for how bias can arise in various stages of algorithm development, and how it can be mitigated. That starts with training and education. In addition, we need to develop robust quality management systems for monitoring and documenting an algorithm’s purpose, data quality, development process, and performance. And, perhaps most fundamentally, we need to build diversity into every aspect of AI development.
Three types of diversity that matter
There are three types of diversity that are critical for building fair AI: diversity in people, diversity in data, and diversity in validation. Let me briefly elaborate on each.
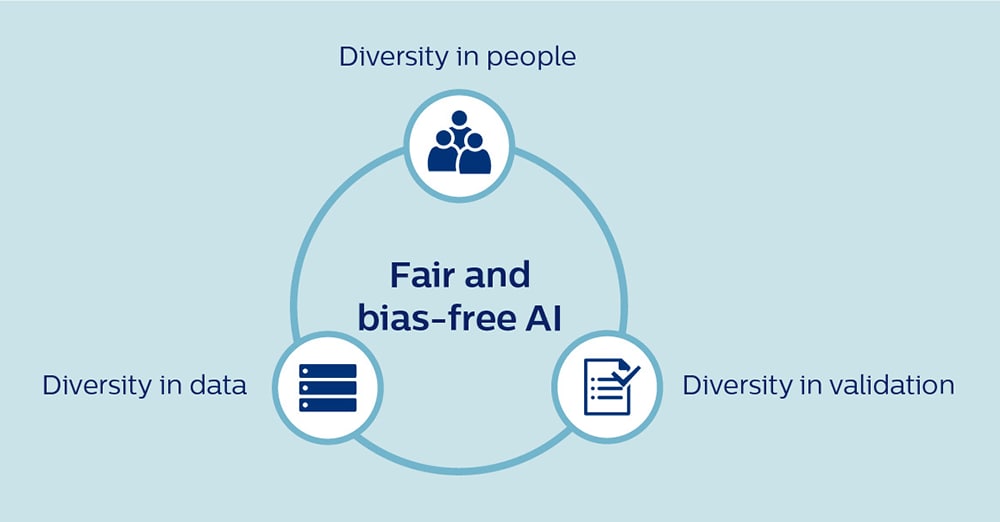
1. Diversity in people First, to make AI bias-free and beneficial for all, it is essential that the people working on AI reflect the diversity of the world we live in. In a field that has traditionally been dominated by white male developers, we should make every effort to foster a more inclusive culture. At Philips, we recently upped our commitments to gender diversity in senior leadership positions, and in the same spirit, inclusion and diversity (whether it’s in gender, ethnicity, or professional background) will be a priority for us as we continue to expand our capabilities in AI and data science. Equally important is that we promote intense collaboration between AI developers and clinical experts to combine AI capabilities with deep contextual understanding of healthcare. For example, when there are known differences in disease manifestation between men and women or different ethnic groups, clinicians can help validate whether algorithmic recommendations are not inadvertently harming specific groups. To further complement that expertise, statisticians and methodologists with in-depth knowledge of bias and appropriate mitigation strategies are another vital asset to AI development teams. Only by true multidisciplinary cooperation will we be able to harness each other’s strengths and compensate for our individual blind spots.

2. Diversity in data Limited availability of (high-quality) data can be a significant hurdle in developing AI that accurately represents the target population. To promote the development of fair and bias-free AI, we should aim to aggregate larger, well-annotated and curated datasets across institutions – in a safe and secure way that protects patient privacy. For example, the Philips eICU Research Institute was established by Philips as a platform to advance the knowledge of critical care by collating de-identified data from more than 400 participating ICUs in the US. The data repository has been used to develop AI tools for critical care, including an algorithm that helps decide whether a patient is ready to be discharged from the ICU. In the context of COVID-19, researchers have also called for broader sharing of patient data across institutions and even countries to ensure that clinical decision support algorithms are developed from diverse and representative data sets, rather than from limited convenience samples in academic medical centers [8]. 3. Diversity in validation Once an algorithm has been developed, it requires thorough validation to ensure it performs accurately on the entire target population – and not just on a subset of that population. Algorithms may need retraining and recalibration when applied to patients from different countries or ethnicities, or even when they are used in different hospitals in the same country. Encouragingly, we have observed in our own research based on the eICU data repository that algorithms derived from multi-hospital data tend to generalize well to other US hospitals not included in the original data set. But careful scrutiny is always needed. For example, when we tested some of our US-developed eICU research algorithms in China and India, we found that local retraining was required. Because the risk of bias needs to be carefully controlled for, we also need to have strong guardrails in place around the use of self-learning AI. An algorithm may be carefully validated for the intended use prior to market introduction, but what if it continues to learn from new data in hospitals where it is implemented? How do we ensure that bias does not inadvertently creep in? As regulators have also recognized, continuous monitoring will be necessary to ensure fair and bias-free performance.
A fairer future for all
Much work remains to be done, but I believe that with appropriate diversity in people, data, and validation, supported by strong quality management systems and monitoring processes, we can successfully mitigate against the risk of bias in AI. Even better, could we make healthcare fairer by tailoring algorithms to specific patient populations, including historically disadvantaged or underrepresented groups?
Could we make healthcare fairer by tailoring algorithms to specific patient populations, including historically disadvantaged or underrepresented groups?
For example, knowing that coronary heart disease has traditionally been under-researched, underdiagnosed, and undertreated in women [11], could we develop algorithms that are specifically geared toward detecting or predicting female manifestations of the disease? In an era of precision medicine, where we are increasingly moving from a one-size-fits-all to a personalized approach to healthcare, it’s an interesting avenue for further research – which should of course fully respect ethical, legal, and regulatory boundaries around the use of sensitive personal data. In the future, I can imagine it will be possible to tune an algorithm to a specific target patient population for optimal and bias-free performance. This could be another step towards a fairer and more inclusive future for healthcare – supported by AI that not only acknowledges variation between different patient groups, but is designed to capture it. References [1] Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366, 447–45. https://doi.org/10.1126/science.aax2342 [2] HIMSS (2019), commissioned by Philips. Artificial intelligence and machine learning in healthcare. Survey conducted among 234 respondents in US healthcare organizations. [3] Goddard, K., Roudsari, A., & Wyatt, J. (2012). Automation bias: a systematic review of frequency, effect mediators, and mitigators. JAMIA, 19(1), 121–127. https://doi.org/10.1136/amiajnl-2011-000089 [4] Feldman, S., Ammar, W., Lo, K., et al. (2019). Quantifying sex bias in clinical studies at scale with automated data extraction. JAMA, 2(7): e196700. https://doi.org/10.1001/jamanetworkopen.2019.6700 [5] Redwood, S., & Gill, P.S. (2013). Under-representation of minority ethnic groups in research - call for action. Br J Gen Pract. 63(612): 342-343. https://doi.org/10.3399/bjgp13X668456 [6] Popejoy, A., & Fullerton, S. (2016). Genomics is failing on diversity. Nature, 538(7624):161-164 http://doi.org/10.1038/538161a [7] Adamson, A., & Smith, A. (2018). Machine learning and health care disparities in dermatology. JAMA Dermatology. 154(11):1247–1248. https://doi.org/10.1001/jamadermatol.2018.2348 [8] Röösli, E., Rice, B., & Hernandez-Boussard, T. (2020). Bias at warp speed: how AI may contribute to the disparities gap in the time of COVID-19. JAMIA, ocaa210. https://doi.org/10.1093/jamia/ocaa210 [9] Cirillo, D., Catuara-Solarz, S., Morey, C. et al. (2020). Sex and gender differences and biases in artificial intelligence for biomedicine and healthcare. npj Digit. Med. 3, 81. https://doi.org/10.1038/s41746-020-0288-5 [10] Goulart, B., Silgard, E., Baik, C. et al. (2019). Validity of natural language processing for ascertainment of EGFR and ALK test results in SEER cases of Stage IV Non-Small-Cell Lung Cancer. Journal of Clinical Cancer Informatics. 3:1-15. https://doi.org/10.1200/CCI.18.00098 [11] Mikhail G. W. (2005). Coronary heart disease in women. BMJ (Clinical research ed.), 331(7515), 467–468. https://doi.org/10.1136/bmj.331.7515.467 Notes [i] Based on their analysis, the researchers later went on to work together with the developers of the algorithm to reduce the racial bias.
Share on social media
Topics
Author

Henk van Houten
Former Chief Technology Officer at Royal Philips from 2016 to 2022
Related news
-
![AI is changing how care is delivered today]()
June 11, 2026
-
June 11, 2026
-
![The future of AI in radiology is the AI you barely notice]()
November 17, 2025
-
![Making the case for systemic change in healthcare]()
October 25, 2023



