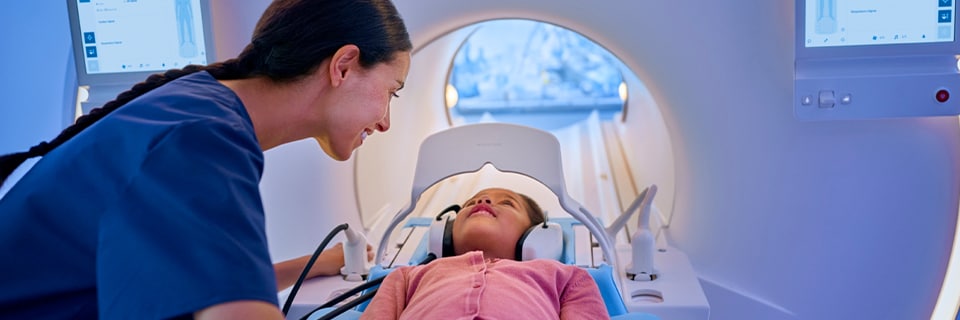
People- and patient-centric innovation for maximum impact
Start with the patient or consumer
Innovation at Philips starts with identifying real needs and then work backwards from those needs, so our innovations are truly people- and patient-centric.
Work together with the physician
We work together with clinicians to co-create solutions that fit real clinical workflows through long-term partnerships.
Focus on impact
We maximize the impact of our innovations by focusing on the ones that have the potential to scale and benefit as many people as possible, so we can help deliver better care for more people.
Learn more about our innovation impact
Ultrasound AI solutions
From image acquisition to analysis, our ultrasound AI solutions integrate into clinical workflows and augment user skills. Clinicians stay in control of the ultimate decision.
Radiology Operations Command Center
Radiology departments can do more with less by connecting experts with technologists and providing cross-training.
BlueSeal magnet
Philips BlueSeal makes helium-free MR operations the new reality, addressing helium scarcity while securing the future for all MR patients.
Turning possibilities into great innovations
~9% of sales
invested in R&D
in 2024
~50%
software/data science focus in R&D in 2024
50,500
patent rights
#1 company
for MedTech patent filings
with European Patent Office in 2025
Clarivate Top
100 Global Innovator ™
13th year in a row
~9% of sales
invested in R&D
in 2024
~50%
software/data science focus in R&D in 2024
#1 company
for MedTech patent filings with European Patent Office in 2025
50,500
patent rights
Clarivate Top 100 Global Innovator ™
13th year in a row
Philips Intellectual Property & Standards
Supporting innovation and new business opportunities by offering access to Philips IP, know-how, technologies and brand licenses.






